Arthur Turrell, Nikoleta Anesti and Silvia Miranda-Agrippino.

As the American playwright Arthur Miller wrote, “A good newspaper, I suppose, is a nation talking to itself.” Using text analysis and machine learning, we decided to put this to test – to find out whether newspaper copy could tell us about the national economy, and in particular, whether it can help us predict GDP growth.
The Bank of England has several models which produce a ‘nowcast’ of GDP growth: an estimate of the growth rate of the economy in the current quarter, before official estimates become available. Think of these models as like trying to predict the end result of a football match before the end of the game: when the match starts, you only have previous games to go on; during the match you start to get an idea of what’s happening, but any prediction you make could still be wrong because the match hasn’t actually finished.
Nowcasting GDP is difficult because it takes time for the official data to be compiled, even once events have taken place. Given this delay in publication, nowcasting has been traditionally conducted with the aid of more timely information from ‘soft’ indicators, like business and consumer surveys. For example, IHS Markit asks firms about the overall level of business activity in the current month compared to last month, and about their expectations for the next twelve months, and publishes results shortly after the close of the reference period. However, because of their nature, surveys can be expensive to run at large scales, and may not be readily available for all countries.
Enter the news. Newspaper copy is influenced by, or influences, economic activity, often on a daily basis. So could it function like even more timely survey data, and give us an early indication of what growth will be like in the current quarter?
Turning news into confidence indicators
To find out, we used text from the daily newspaper The Guardian. We chose this paper on account of it being free and easy to download; other news sources may have generated different results. We analysed articles covering business, politics, and economics using two cutting-edge algorithms for turning news into numbers. One, recently published by Nyman et al., uses a method of counting words related to economic sentiment. It is constructed by counting the number of pre-defined positive and negative words in news articles. Each article, 
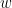
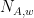

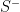

So the score for an article “The quick brown fox jumps over the lazy dog”, with an empty positive dictionary and a negative dictionary consisting of (“lazy”, “bad”) would have a per word score of -1. Aggregating this score over many articles and days gives a picture of sentiment over time. We call this NI1 News Indicator 1 (Nyman).
The second approach finds exact matches to pre-defined lists of words but it also counts words which are semantically similar to words in the positive and negative dictionaries. It uses a machine learning algorithm, developed by Tomas Mikolov at Google, which can ‘remember’ relationships between words and find those that are close together. It does this by creating a numerical representation, a ‘vector’, for every word. Once words are represented as numbers, we can compare how similar they are. For example, the closest word vector 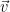
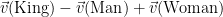
is 

Figure 1: This shows schematically how each word gets represented as a vector in multiple dimensions (three dimensions shown) using the algorithm. The vector created by combining King and Woman, and subtracting Man, results in a vector which is closest to the vector for Queen.
Importantly, two words which are semantically similar but not exactly the same are picked up by this method, but with a weight between zero and one; so if ‘recession’ were in the negative dictionary with a score of -1 but ‘slowdown’ were not, this method would still count ‘slowdown’ but with a score between 0 and -1. We use several dictionaries1 which capture both positive and negative words and run the algorithms over articles in The Guardian that cover economic and financial topics. For example, the positive words include ’boost’, ‘improved’, and ‘strength’, while the negative words include ’irregularities’, ’threat’, and ’exacerbate’. These similarity scores, and their polarities, are then summed just like in the first approach. We label this second variable NI2 News Indicator 2 (Mikolov).
To get a sense of the type of signal that can be picked up by the news-based confidence indicators, we plot both NI1 News Indicator 1 (Nyman) and NI2 News Indicator 2 (Mikolov) against the preliminary estimate for the UK quarter on quarter GDP growth rate (Figure 2). Indeed, they seem to pick-up potentially relevant signals for the current state of the economy.

Figure 2: Quarter on Quarter UK GDP Growth, preliminary estimate (dark blue line), The Guardian-based economic sentiment scores (light blue and red lines).
Can the news tell us about what’s happening in the economy now?
We used the two text-based confidence indicators in the nowcasting model developed in Anesti et al. (2018), as a follow up and extension of Giannone et al. (2008).
The model mimics the way policymakers and market participants usually produce and subsequently revise forecasts; they monitor numerous data releases in real-time to form a view on the current state of the economy that they then update when the data outturns differ from their expectations. This framework enables us to use a wide set of indicators that correlate fairly well with GDP growth, and to assess the predictive content of the newly constructed text-based measures against more standard predictors within an established nowcasting model through model-based weights2. These give an indication of the relative importance of all the input variables in providing a reliable signal about the current state of the economy. We report such weights in Figure 3 for a selection of the variables included in the model for all the three months of every nowcast quarter (i.e., M1 is the first month of the reference quarter, M2 is the second and M3 is the third).

Figure 3: Relative weights of economic indicators in forecasting current economic activity in the three months of every reference quarter.
This reveals a few interesting features of the text-based confidence indicators. First, their importance in forecasting current economic activity is comparable to a range of high profile indicators, including the Index of Services, retail sales, equity prices and other confidence indicators, which are typically regarded as leading the economic cycle. Second, similar to the surveys and other more timely indicators such as the slope of the term structure of interest rates, the relevance of the text-based indicators decreases within the quarter, when other official data relative to the current quarter become available. Finally, and despite the fact that they are not extracted from a specialist economic publication, the relevance of NI2 is over half the size of the IHS Markit/CIPS PMI indicator, which has come to be considered the single best survey-based predictor of current economic activity followed by many central banks and market participants.
News based series have complementary features as compared to surveys. They offer a timely window onto the views of millions of readers. We can tailor their release time within the data cycle – online newspapers are updated minute by minute so there is no restriction on when news-based confidence indicators can be ‘published’. We are currently looking at whether their information content can be further enhanced by refining the methods used for their construction, as well as by broadening the pool of newspaper articles included so that it covers different demographics.
News travels fast, and it seems that real-time information about the UK economy is no exception.
1 They are Nyman et al.’s dictionary, the Harvard-IV-4 psychosocial dictionary, and Loughran and McDonald’s financial dictionary.
2 These weights are solely calculated based on the model and they don’t necessarily represent the way the Bank of England’s staff is processing the data flow or weighting different pieces of information for nowcasting UK GDP growth.
Arthur Turrell works in the Bank’s Advanced Analytics Division, Nikoleta Anesti works in the Bank’s Current Economic Conditions Division and Silvia Miranda-Agrippino works in the Bank’s Monetary and Financial Conditions Division.
If you want to get in touch, please email us at bankunderground@bankofengland.co.uk or leave a comment below.
Comments will only appear once approved by a moderator, and are only published where a full name is supplied. Bank Underground is a blog for Bank of England staff to share views that challenge – or support – prevailing policy orthodoxies. The views expressed here are those of the authors, and are not necessarily those of the Bank of England, or its policy committees.
Interesting work! Wondering if there is a way I would be able to replicate the indicator derivation based on news of other countries?
You write: ‘News based series have complementary features as compared to surveys. They offer a timely window onto the views of millions of readers.’ But how do you know that what appears in a newspaper corresponds to the views of its readers? An even if it does so correspond, what is the direction of causation?